鯖缶のなかみは鯖です。
この記事はフレカフェ&きりたん丼合同Advent Calendar 24日目の記事になります。
ごあいさつ
どうも。あほくすです。こんばんわ♪
もうすぐクリスマスですね!クリスマスにむけて,マストドン楽しんでいますか?
本日は鯖缶のなかみについて語りたいと思います。
鯖缶のなかみはなんでしょう?

鯖缶のなかみは鯖です。
サーバー管理者にとっての鯖はサーバーです。
サーバー管理者はサーバーについて,誰よりも詳しくなければなりません!
しかし,サーバーは略して鯖です。サーバー管理者は鯖缶です。
ということは,鯖缶を仰せつかっております,我々サーバー管理者は,やはり鯖についても詳しくなる必要があるのではないでしょうか?
というわけで
鯖を買ってきました。

いや。本当は鯖缶を買って写真を撮って満足するつもりだったのです。
しかし,店頭の鯖缶をどれだけ眺めてみても,缶に鯖ちゃんが描かれていない!!!!!鯖が描かれた鯖缶がほしくてきたのに漢字で「鯖」とか,既に切り身になって調理された「鯖の味噌煮」しか無いではありませんか。
これではいけない。やはり鯖缶の記事たるもの生前の鯖の御姿を載せなければならない…。などと思考が迷走した結果,台所には鯖がいたのです。
鯖を捌こう。
鯖を買ってしまったからには鯖かなければ捌かなければならない…。
しかし,魚なんていつも切り身で買ってきているから捌いたことはない。
仕方がないのでYoutubeで「鯖 捌き方」でググってみつかった「日本さばけるプロジェクト」(以下,「鯖プロ」という。)という謎のサイトの動画にならって捌いてみました…。

鯖プロさんによると,はじめに鱗を取るみたいなんですが,既に鱗は無いみたい?包丁ですーりすーりしていましたが収穫なし。

頭をシュパッっと切り落として。お尻のほうから腹を切り開いて,内臓をプッツンと切って取り除きました。
血合いの取り方が動画だけではよくわからなかったので,別で検索してからやったけれど,なんだか思ったより簡単。

おなかのほうから骨にそってなんとなく切り開いて。
まな板をひっくり返して背中側もなんとなく切り開きました。
なんか。頭のほうの背びれ周辺が硬かったです。が,まぁ,頑張ったら切り開くことができました。
骨に沿ってすいーっと身を切り離すのは割と失敗しなさそう。

裏返して同じように開いてみた。裏も表も難易度はそう変わらず。

最後に骨を取ったら終わり。

冷蔵庫の中で,酒・みりん・醤油に1時間ほど漬けて,フライパンで焼いて食べました。美味しい。鯖おいしい!
ごちそうさまでした。
えっと。これで記事は終わりですかって?
いや。本当は技術的な鯖缶のなかみについての記事を書いていたんですがね。まだ書ききれていないので,苦肉の策で鯖の記事で繋いでみました…。えっと。そうですね。今日中にはなんとか。なんとか記事を書き上げて,本記事に追記して完成させたいと思いますので,明日また見に来てもらいたいです。よろしくお願いいたします。
というわけで。今年の仕事はもうちょっとばかり続くんじゃよ。
ちゃんと書ききって来年を迎える準備をしなきゃ!!!!
では,またあした。
【追記】12/25追記
どうも。メリークリスマス!
あほくすです。こんばんわ。
鯖の記事だけじゃと「そっちか~~~~い!」ってなりましたので,フレカフェのサーバーについてちょっとだけ書くのです。
興味があれば読んでみてくれると鯖缶の中身(サーバー管理者?)が喜びます。
1.マストドンはどうやってうごいているの?
サーバー構成を説明する前に,マストドンってそもそもどういう動きをしてるのよ…?ということがわからないと珍紛漢紛(ちんぷんかんぷん)だと思うので,かるく説明します。(まちがってたらゴメン)
ざっくりこんな感じで動いています。
2. マストドンインスタンスの構成要素
1.で紹介したマストドンインスタンスの構成要素について説明します。
(1)puma
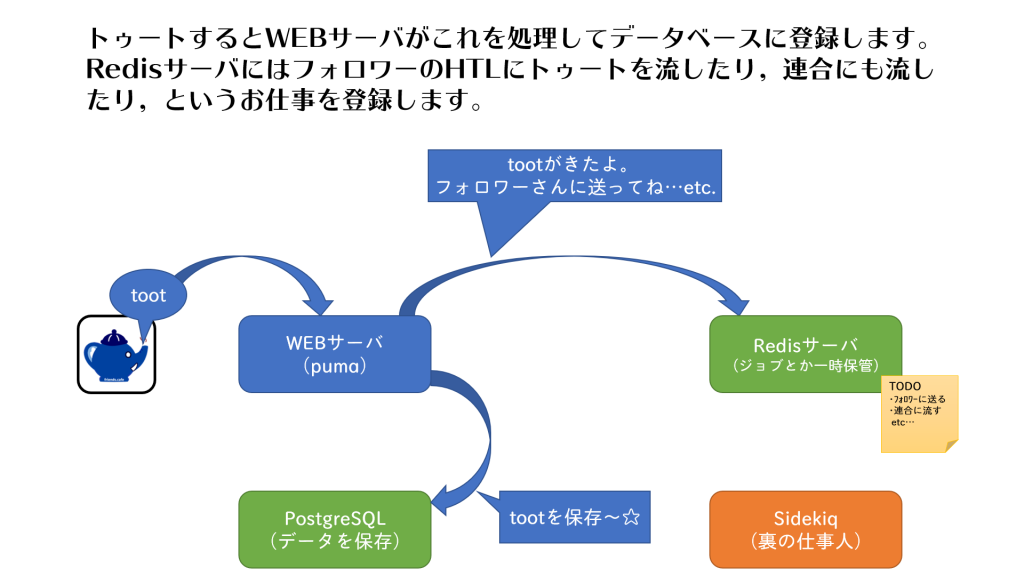
pumaはRubyで作られたウェブサーバーで,普通にログイン画面を表示したり,利用規約を表示したり,認証をしたり,単体のトゥートを表示したりします。また,みなさんからのトゥート(投稿)を受付するお仕事もこなしています。「トゥート」ボタンを押すとpumaさんが呼び出されているのです。
もう少しサーバ寄りの説明をすると,pumaはRuby のRack というインターフェイスに対応した並列処理が得意なWEB サーバです。あらかじめ,いくつかのスレッドをプール(待機)させていてサーバにアクセスがあるとプールしてたスレッドにお仕事をおまかせするので,すばやい応答ができます。
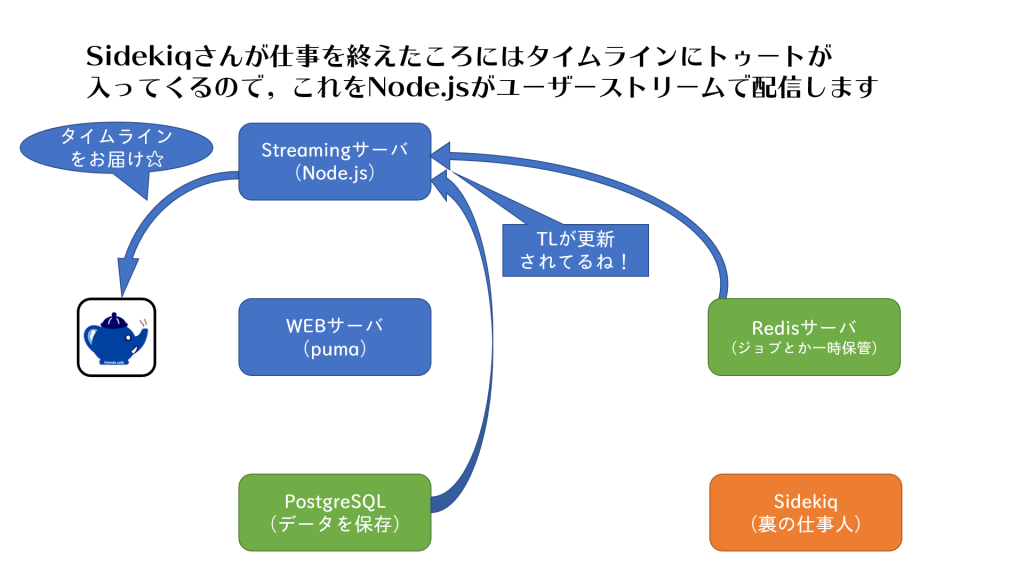
(2)Node.js
Node.jsはサーバー上で走るjavascriptで,各種タイムラインをユーザーストリームを使って配信しています。
pumaがユーザーがブラウザからアクセスするたびに何かを表示するのに対して,Node.jsはブラウザとの接続をつなぎっぱなしにしてタイムラインに更新があるたびにトゥートのデータを自動的に送ってくれます。
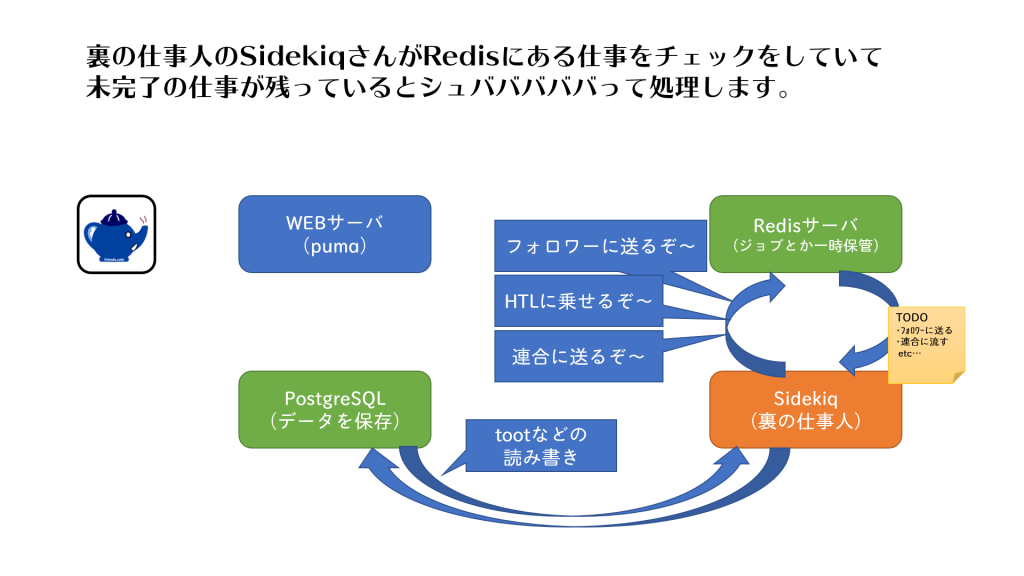
(3)Sidekiq
Sidekiqはサーバーの裏側でせっせとお仕事をこなす人です。
フォロワーのタイムラインにトゥートを送信したり,ユーザーに通知を送ったり,連合にトゥートを送信したり,連合からのトゥートをローカルのユーザーに送信したり,ユーザーがURLを含むトゥートをしたらそれに対応するカードを生成するためにリンク先を取得しに行ったり,いろいろな仕事をしています。
(4)PostgreSQL
PostgreSQLはトゥートのデータを保存するためのデータベースです。
この子が倒れるとマストドンはおしまいです。すべてのユーザー情報とかトゥートの情報はこの子が管理しています。
(5)Redis
RedisもPostgresSQLのようにデータを保存するデータベースなのですが,こちらは永久保存ではなくて一時仮置きに使われています。
pumaからSidekiqに仕事を依頼するときにはRedisのデータベースに仕事の情報が登録されていきます。また,Redisはメモリ上で動作してストレージの読み書きを少なくしているので,より高速に動作する特徴があるようです。
3.サーバの分割
friends.cafeでは1つのサーバーに全部の機能を入れているのではなく,8個くらいのサーバーに機能を分けて載せています。その理由を簡単に説明しておきます。
(1)サーバの冗長性
冗長性(じょうちょうせい)というのは,同じ機能を持つサーバーを複数用意することで,どれかのサーバーが壊れてもサービスを継続できるようにすることです。
例えば,PostgreSQLのサーバーは,SSDが故障するとデータを喪失して復旧できなくなってしまいます。そのため,バックアップのサーバーを用意して,常にデータのコピーを取っておくことで,片方が壊れてもデータを復旧することができるようになります。
(2)負荷分散とスケールアウト
マストドンは利用者が増えるとサーバーの負荷が大きくなります。
大きな負荷に対処するためには,たくさんのCPUとおおきなメモリが必要になるのですが,これまで紹介してきたマストドンの構成要素ごとに,メモリを増やすと効果的に性能アップするのか,CPUのほうが効いてくるのか,はたまたSSDの性能が必要なのか変わってきます。
さらに,一定以上の負荷を超えると,1台のサーバーに搭載可能なCPUやメモリでは対処できなくなるので,複数台のサーバーを用意して,負荷を分散させる必要があります。このように,性能アップのためにサーバー台数を増やすことをスケールアウトといいます。(単純な性能アップはスケールアップ)
friends.cafeでは今のところ大した負荷はないのですが,もしスケールアウトしたいなーとなった場合,あらかじめスケールアウトしやすいように,マストドンの構成要素ごとにサーバーを分割しておかなければ,負荷が増えたからスケールアウトしようと思ってもなかなかサーバーの構成を変えるのが大変です。(それまではサーバー内部でやりとりしていたものをネットワーク上の別サーバーにアクセスしに行く設定に変更しなければならないとか。データベースファイルをちゃんと移行しないといけないとか…。) なので,friends.cafeでは運用開始時からあらかじめマストドンの構成要素ごとにサーバーを分けてあります。
4.個別のサーバについて
ここで,フレカフェの実際のサーバ構成をみてみましょう。
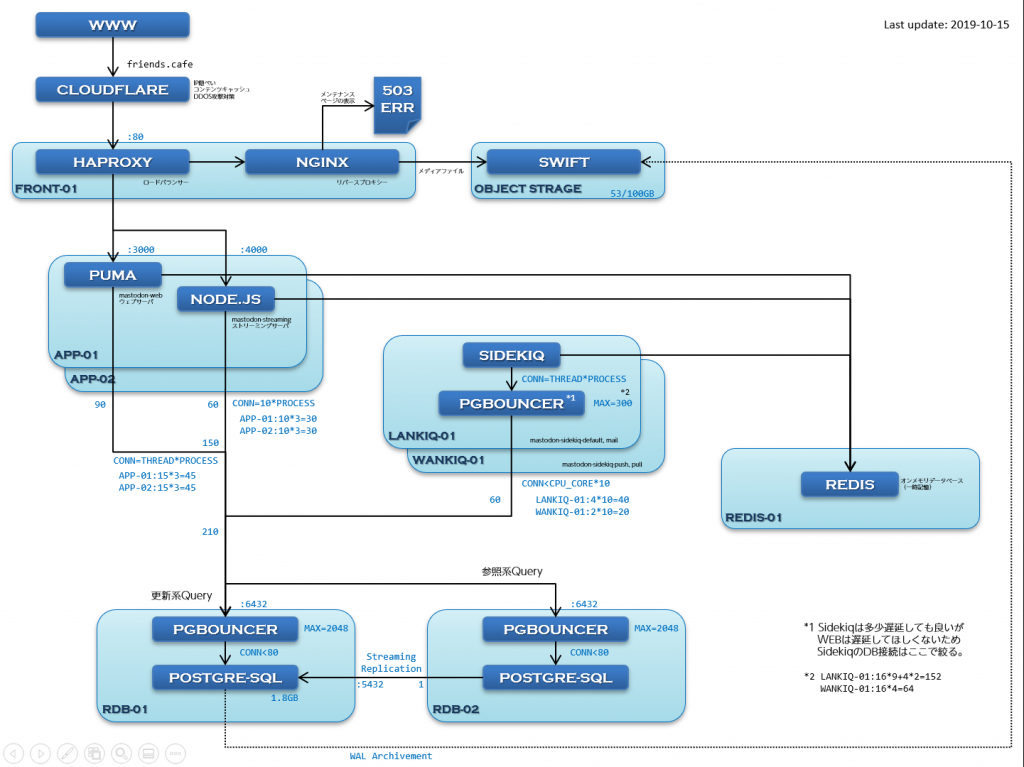
これまで説明してないものもいろいろありますが,1つずつ役割と設定のポイントを見ていきましょう。
(1)アプリケーションサーバ(APP-01, APP-02)
このサーバーは実際にインターネットを通してユーザーからアクセスされる機能であるpumaとNode.jsを配置しています。
pumaとNode.jsはユーザーに対する応答を実際に行うサーバーなので,他の機能とは独立させておいたほうが安定した応答速度での運用が期待できます。また,負荷が増えてきた際にサーバーを追加して,負荷分散することが可能です。
【puma】
pumaはthreadをプールしてユーザーからのアクセスを待ち受けます。
設定としてはスレッド数とプロセス数があります。
google先生によれば,スレッド数は最大で15くらいまで,プロセス数はCPUのコア数と同じにすると良いようです。
systemdの設定を次のようにすればOK。
MAX_THREADS=15
WEB_CONCURRENCY=3(CPUのコア数)
/etc/systemd/system/mastodon-web.service
【Node.js】
Node.jsはシングルスレッドプロセスで,設定できるのはプロセス数のみです。
プロセス数は標準では自動的にCPUのコア数-1になります。
CPUのコア数と同等まではプロセスを増やしても安定して動作するので以下のようにしています。
STREAMING_CLUSTER_NUM=3(CPUのコア数)
/etc/systemd/system/mastodon-streaming.service
【ImageMagickの最適化】
アプリケーションサーバーではアップロードされた動画像をImageMagickで変換しています。この処理も場合によっては重いので,なるべく軽量に動作するようチューニングしておきたいものです。
こちらとかこちらで紹介されている内容をもとに自前でコンフィグしてインストールします。
一部のソースコードを編集したのち…
define CacheShift 2
ImageMagick-7.0.8-40/MagickCore/quantize.c
↓
define CacheShift 3
次のコンフィグでインストールしました。
–with-quantum-depth=8 –disable-hdri
これにより,ImageMagickのメモリ使用量が削減される。
【jemallocの使用】
Tuning Mastodon にも 記載のあるように,jemallocを導入することでpumaやsidekiqのメモリ使用量を削減することができます。
(2)Sidekiqサーバ(LANKIQ-01,WANKIQ-01)
このサーバーはSidekiq専用のサーバーです。
Sidekiqはたくさんの仕事をこなすため,独立したサーバーにしておくと,忙しいときも他の機能に影響がなくて良いです。なお,起動するプロセス数に応じてサーバーの搭載メモリの量を増やす必要があります。
Sidekiqはサーバーの台数さえ増やせば増やした分だけ処理速度を増せるので,キューが溜まってしまうようなら+1台って感じでサクッとスケールアウトできます。
【Sidekiq】
起動するSidekiqプロセスの数は空きメモリの様子を見ながら調整します。
Sidekiqプロセスにとって最適なスレッド数は,諸説ありますが,当サーバーでは現在16スレッドにしています。各Sidekiqプロセスで処理するキューの種類は起動時のパラメータで指定することが可能です。役割を限定するときは,以下の4種類の中から選択します。
1.Default
ローカルのトゥートなどを処理するキューです。
これが一番たくさん必要です。
キューの処理が溜まってしまうと,ホームやローカルタイムラインの遅延につながります。
2.Mail
メール配信用のキューです。
1プロセスあれば十分かなと。
3.Push
ローカルのユーザーのトゥートをリモートへ配信するキューです。
多少遅れても問題ありませんので,LTLメインのサーバーではDefaultより少なくても良いかも。
4.Pull
連合のトゥートを処理するキューです。
このプロセスは強すぎると,連合から大量のトゥートが配信されてきた際に,サーバー全体(主にみんなが共用しているデータベースサーバー)の負荷を高めてしまいます。なので,多少連合のトゥートを取りこぼしてもいいかなと思えれば,あえてプロセス数を少なく制限するのも手です。
【 PgBouncer 】
当サーバーではSidekiqサーバーからデータベースサーバーへの接続数を制限するために,Sidekiqサーバー側にもPgBouncerを導入しています。
PgBouncerは,データベース接続をキャッシュして,データベースサーバーの負荷(メモリ使用量)を軽減するものです。
Sidekiqサーバでは,メモリがある限り,たくさんのSidekiqプロセスを立ち上げて,それぞれのプロセスが大量にデータベースサーバーにコネクションを張りに行くことになるので,一旦Sidekiqサーバー内でPgBouncerによりデータベースへの同時接続数をキャッシュすることでネットワーク負荷軽減を図っています。
(3)オブジェクトストレージ(SWIFT)
オブジェクトストレージというのは,安価で大容量なハードディスクみたいなものです。100GBあたり毎月450円で使えて,VPSのコンパネから100GB単位で簡単に容量アップが可能です。
当サーバーでは,マストドンにアップロードされるメディアファイルはすべてオブジェクトストレージへ保存しています。今のところ,200GB契約のうち80GBが使用済みとなっています。
【SWIFT】
Conohaちゃんが採用しているOpenStackのオブジェクトストレージです。
~mastodon/live/.env.productionの# Swift (optional) の行の下にて,SWIFT_ENABLED=trueとして,SWIFT_USERNAME, SWIFT_TENANT, SWIFT_PASSWORD, SWIFT_AUTH_URL, SWIFT_CONTAINER, SWIFT_OBJECT_URLを設定してあげれば使えます。
(4)フロントエンドサーバ(FRONT-01)
フロントエンドサーバは実際に外の世界とつながっているサーバで,ユーザーからのアクセスをそれぞれのアプリケーションサーバへ振り分けて負荷分散しています。
【HAProxy】
HAProxyは負荷分散をするやつです。
ラウンドロビン方式で接続を順次別々のアプリケーションサーバーに振り分けています。また,メディアファイルのURLが要求された場合はNGINXに接続するように指定しています。
【NGINX】
NGINXはWEBサーバーですが,うちではリバースプロキシとして,メディアファイルのURLが要求された際に,実際のオブジェクトストレージ上のデータを送信するように設定しています。
これがないと画像ファイルのURLがConohaのVPSのオブジェクトストレージサーバーのURLである https://object-storage.***.conoha.io/v1/ユーザーID/コンテナ名 を直で指してしまいますのでかっこわるいのです。
(5) データベースサーバ (RDB-01,RDB-02)
データベースサーバーにはPostgreSQLが使われています。
当サーバーではデータベースサーバーを2台使っていて,Streaming ReplicationによるHot Standby構成(通称SR+HS構成)になってます。SR+HS構成ではMasterに更新系クエリを含むすべてのクエリを,Slaveに参照系クエリを処理させることができるので,2台のデータベースサーバーを使って参照系クエリの負荷軽減が可能です。この負荷分散のためにはMastodonのデータベース接続設定の箇所でMakaraドライバーを使用します。
また,PostgreSQLは接続ごとに作業用メモリを確保するため,接続数の上限はメモリ搭載量に左右されます。何も対処しないとすぐに接続数の上限に到達してしまうため,接続をキャッシュしてメモリ使用量を減らすためにPgBouncerにてトランザクションベースのコネクションプールを行います。
あとはおまけですが,当サーバーではPostgreSQLのサーバーが全部故障してもデータ復旧が行えるように,オブジェクトストレージにWALをアーカイブしています。3重の障害対策がされていて,かつ,安価なオブジェクトストレージにWALを保存することで,データ喪失のリスクを減らそうという試みですね。
【Streaming Replication】
ストリーミングレプリケーションは,マスターDBの更新情報をスレーブDBへ転送してデータベースを複製するものです。多少の遅延はありますが,わりと高速に複製することができ,複製したデータベースを用いて,負荷分散や障害時のフェイルオーバーが行えるようになります。(うまくやれば自動的なフェイルオーバーが行えるのだけど,当鯖では使用していません。何かがあったときは手動でフェイルオーバーさせます。)
【Makaraドライバー】
データベースの負荷分散のために,マスタDB用の更新系クエリとスレーブDB用の参照系クエリを分けてくれるものです。
Tuning MastodonのUsing read replicasに設定例の記載があります。
【PgBouncer】
PgBouncerはアプリケーションからデータベースの接続をキャッシュするものです。実際のデータベースへの接続はPgBouncerが代表して接続しっぱなしになっています。アプリケーションからPgBouncerへ接続要求があると,PgBouncerは既存のデータベース接続を利用してトランザクションを実行してその結果を返します。複数の接続要求があるときも,限られた接続を使いまわしてくれるので,データベースサーバーの負荷は低くなります。
ただし,設定をトランザクションモードにしておかないと,セッション単位のキャッシュとなってしまうので注意が必要です。セッション単位のキャッシュでは,pumaもNode.jsもsidekiqもセッションを張りっぱなしにしてしまいますのでキャッシュできず意味がありません。(そもそもNode.jsなどは自前でセッション単位のコネクションプール機能を持っており10個のセッションを使いまわしています。)
【WAL Archive】
当サーバーではオブジェクトストレージにWALをアーカイブしています。PostgreSQLからSWIFTへのWAL転送には,WAL-Eを使用しています。
(6)Redisサーバ(REDIS-01)
Redisサーバーは一番スケールアウトが困難なものなのですが,マストドンでは一時的にジョブをためておく程度の使い方なので,実際に使ってみると大したメモリ使用量にもならず,CPU負荷も大きくなかったので,そこまで負荷を気にしなくても良いようです。とはいえ,スケールアウトを想定可能な他のサーバーと共存では他のサーバー側のスケールアウトがしにくくなるので,Redisサーバーも他と独立させています。
5.CDNについて
当サーバーではCloudflareというCDNを使っています。
(1)CDNとは
CDN: Content Delivery Networkとは,複数のユーザーに配信されるデータをCDNサービスを提供している会社のサーバーにキャッシュして,最も距離的に近いところからユーザーに配信することで遅延を小さくするとともに,サーバー側の負荷を低減するサービスです。
(2)Cloudflareについて
Cloudflareは米国のCDNやDDoS対策やSSL対応などのサービスを提供している会社です。
- CDN → ウェブサイトのレスポンスが速くなる
- DDoS対策 → 万一攻撃されても防いでくれる
- SSL対応 → 接続をSSL化してくれる。証明書も自動更新してくれる。
良い点は安いことですかね。基本サービスなら無料で使えます。
うちは共有SSLではなくて専用SSLを使っているので,Proプラン+SSL費で月額25USD支払っています。 Cloudflareによると11/25~12/24の1か月間でfriends.cafeでは25GBの通信があり,そのうち10GBはCloudflareがキャッシュしたデータから配信したようです。画像などをキャッシュしてくれるだけで表示がサクサクしてくれるので効果があるんじゃないかなと思います。
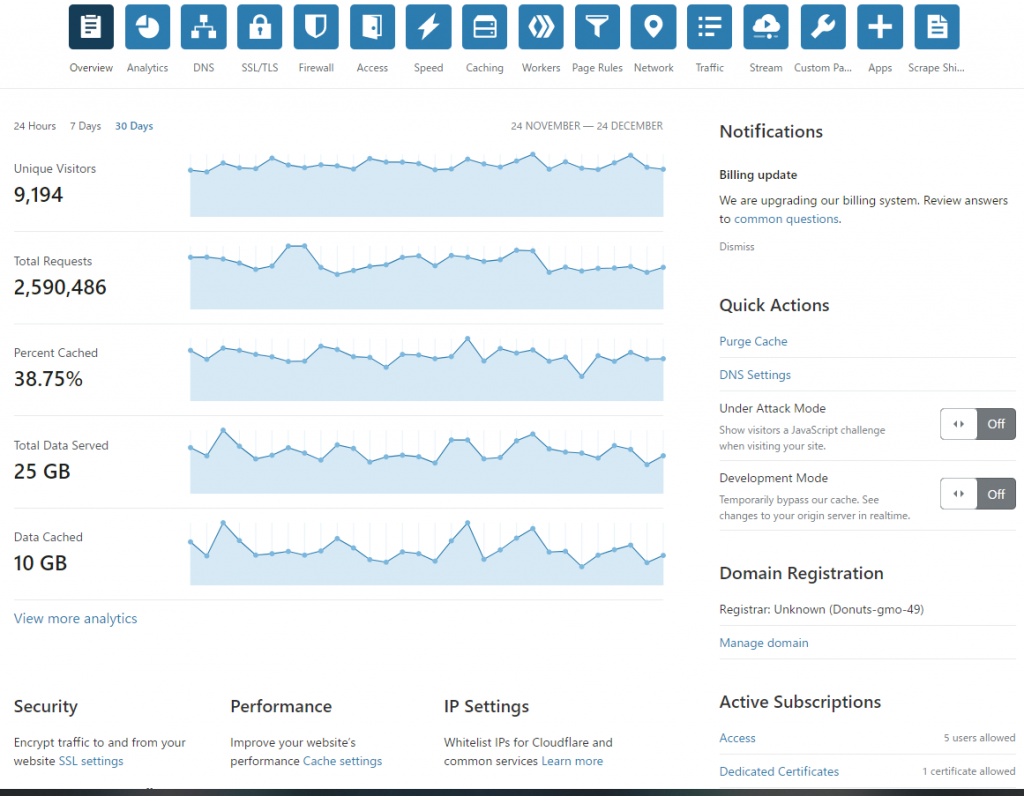
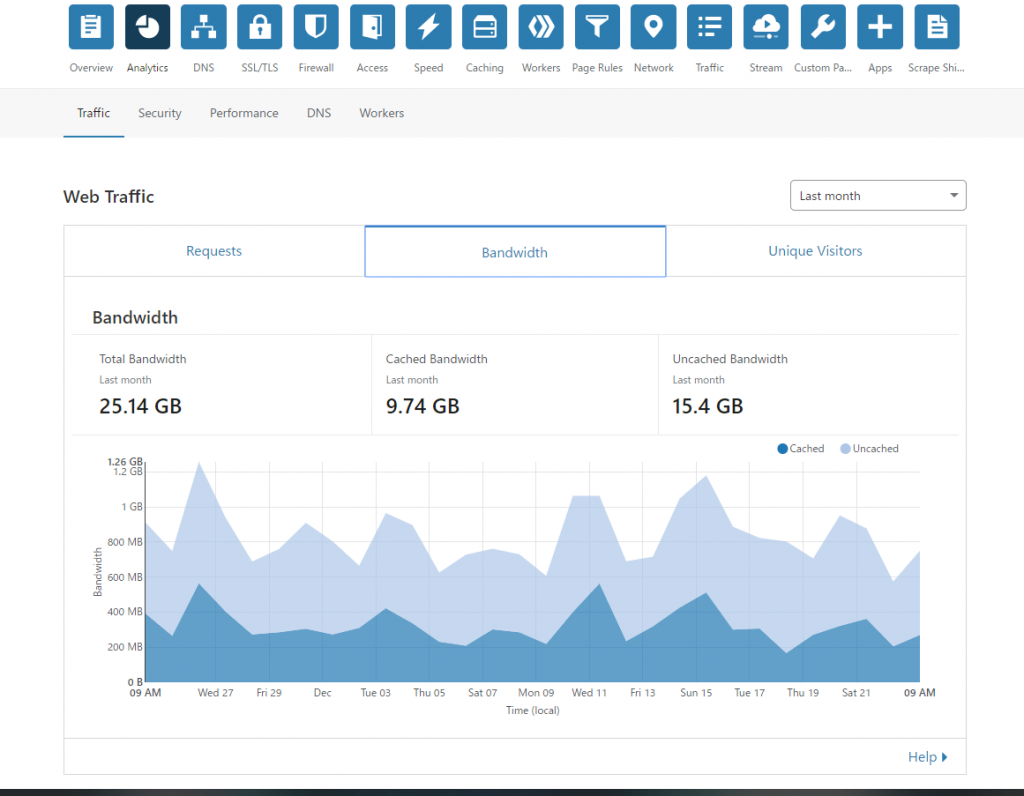
6.サーバーを監視するしくみについて
(1)Sidekiq監視画面(マストドン標準機能)
Sidekiqの監視画面では次の項目を監視することができます。
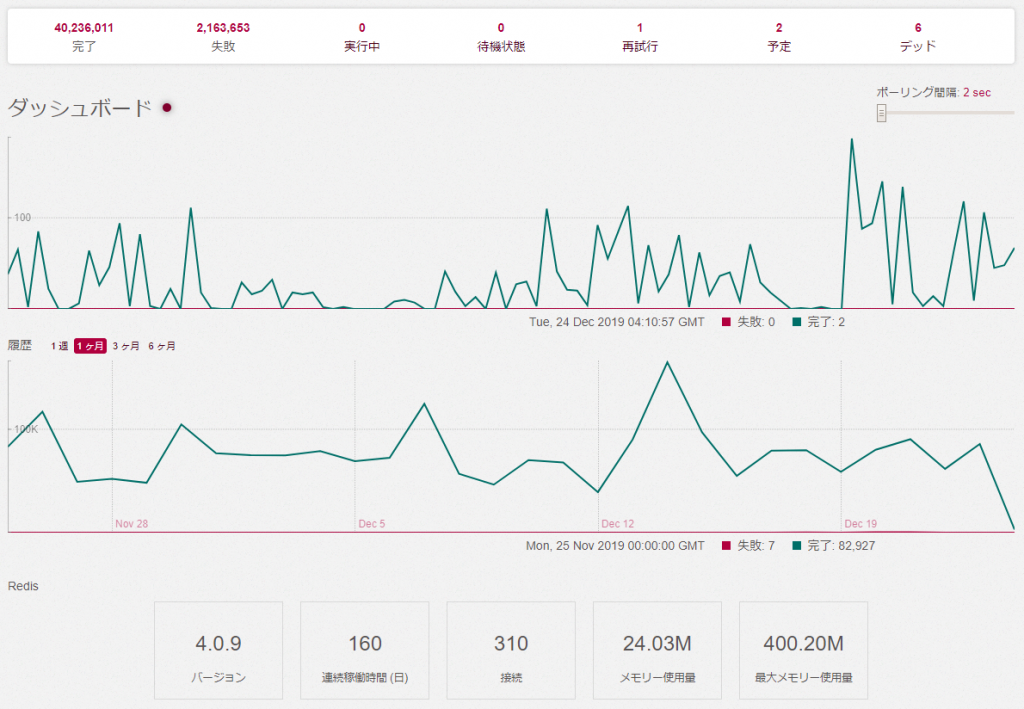
- Sidekiqキューの処理状況,Sidekiqプロセスの実行状況
- Redisサーバーの状態(下方のバージョン,連続稼働時間,接続,メモリー使用量,最大メモリー使用量)
(2)PgHero(マストドン標準機能)
PgHeroでは次のことが確認できます。
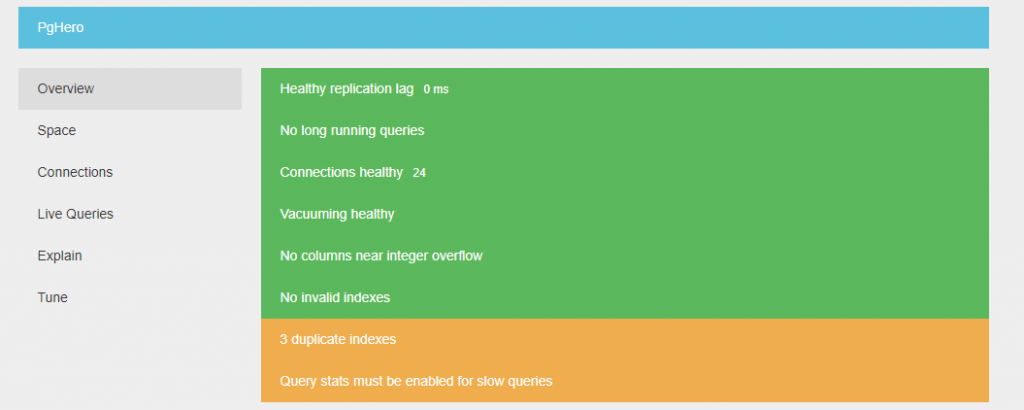
- データベースの接続数,データベースの容量など。
(3)Zabbix
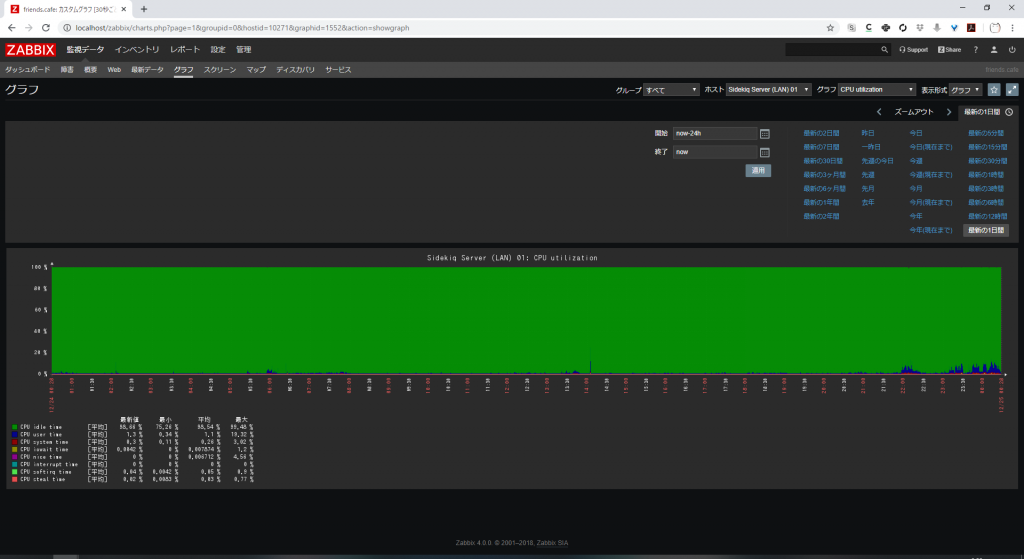
当サーバーではZABBIXという監視ツールでマストドンを起動しているサーバーの状態を一括監視しています。
こんな感じでグラフでCPUやメモリやネットワークの負荷をチェックすることができます。また,任意の条件をトリガーにメールで通知やスクリプトの実行なども可能です。(まだ,設定していない。)
7.過去に発生した不具合と設定ミスについて
(1) タイムラインの遅延
friends.cafeの運用開始から8月に原因を除去するまでの間,まれにホームタイムラインに遅延やタイムスリップしてきた過去のトゥートが表示されることがありました。最初はSidekiqのプロセス数などを疑ってかかったのですが,原因はデータベースサーバーへのコネクションプーリングに使用していたPgpool-IIでした。
【原因はデータベースコネクション】
さて,なんでタイムラインに突然過去のトゥートが表示されたのか。
原因はSidekiqのプロセスが長時間デッドロックしていたからでした。
そしてデッドロックの原因はデータベース接続がいつまでたっても確立しないからで,接続がいつまでも確立しない理由はpgpool-IIがセッションベースのコネクションプーリングをしていたためでした
【PGPOOL-IIではだめだった理由】
根本原因は上に書いた通りpgpool-IIのセッションベースでのコネクションプーリングです。
これを具体的に説明すると,セッションベースのコネクションプーリングというのは,アプリケーションからデータベース接続を開始する際に,過去に同じユーザー,データベース名での接続をしていれば,その過去のコネクションをしばらく維持していて,新しい接続に対して使いまわすというものです。
これは,処理のたびにデータベース接続を開始/終了するプログラムに対して,接続のオーバーヘッドをなくす意味で有用なのです。
しかし,マストドンに用いられているアプリケーションは,pumaにせよNode.jsにせよSidekiqにせよ,データベース接続を自分で張り続けてクエリを処理しています。つまり,自前でセッションベースのコネクションプーリングを行っているのですね。
すると,良くないことが起こります。Pgpool-IIでは,セッションベースのコネクションプーリングを行っているのですが,同時に接続が多すぎると後から接続しに来たアプリケーションを,他のアプリケーションの接続が終了するまで待機させています。
これは,データベースサーバーへの負荷を制限するためなのですが,先ほど説明した通り,マストドンに用いられているアプリケーションは自前でセッションベースのコネクションプーリングを行っているので,セッションを終了しないのですね。
このせいで,あとから接続しに来たSidekiqのプロセスは,永遠に終わらない他のアプリケーションのデータベース接続が終わるのを待っていてデッドロックしてしまったのだと思われます。(pgpool-II側で,何時間もつなぎっぱなしのプロセスの接続は強制切断する設定をしていたので,数時間後に遅延となって表れてくるのでした。)
(2)画像が表示されない不具合
11月になぜかすべての画像だけが表示されない不具合が発生しました。原因はHAProxyとNGINXの接続でエラーが出ていたためで,NGINXを再起動したら正常になりました。
エラーの内容を確認したところ,502エラー【 完全な応答を受信する前に中止 】であって,プロセス同時接続数actconn=104,フロント同時接続数feconn=104となっていました。
確信は持てないのですが,LimitNOFILEの設定かなぁと思ったので,systemdの設定に LimitNOFILE=65536 を設定して,様子見という感じです。(様子見とはいえ,NGINXはずっと再起動してなかったので,症状が出るまで半年くらいかかる)
8.おわり
長々と書いてきましたが,うちのサーバ設定こんな感じ~という雑記であり,自分の備忘録でもあります。
にしても,4月末からサーバーを立ち上げて,5月からサービスを開始して,12月までサーバーを運用してきましたが,少しずつ少しずつマストドンとかLinuxのことがわかってきたかなぁ…?という感じです。
今後もずっとサーバー管理は勉強に次ぐ勉強です。頑張って…なんとか時間を取って,鯖を捌きながらサーバーを捌いていきたいものです。
これを書ききれたので,これで私も安心して年を越せます。
今年は本当にありがとうございました。
来年もまた,よろしくお願いいたします。

1件のコメント
7いお · 2019-12-24 17:44
そっちかーーーい!ww